PROJECT OVERVIEW
Deep Sense is an efficient deep convoluted Net-based model that trains on both audio and video features to predict the represented emotions. This technology was created within 35 hours at the San Diego Global Artificial Intelligence Hackathon in collaboration with two software engineers and two data scientists. The challenge was to build a model that is smart enough to recognize various emotions through voice or facial expressions in an automated process.
Deep Sense is an efficient deep convoluted Net-based model that trains on both audio and video features to predict the represented emotions. This technology was created within 35 hours at the San Diego Global Artificial Intelligence Hackathon in collaboration with two software engineers and two data scientists. The challenge was to build a model that is smart enough to recognize various emotions through voice or facial expressions in an automated process.


MY ROLE
I was the front end developer of the team and was in charge of everything that was visible. I programmed the visual interfaces of the video input page, the analyzed audio-video output page, and the final prediction page. I used HTML, CSS, JavaScript, Three.js, and the OrbitControls JavaScript library for the front end. The back end development technologies that were integrated included Python, Flask and TensorFlow. The two data scientists worked on the deep networks to train the model to predict emotions. The software engineer worked on the integration of the back end code with my front end code. I also designed a logo and logotype for Deep Sense as well as make design refinements to the presentation page and slides.
FRONT END IMPLEMENTATIONS & FEATURES
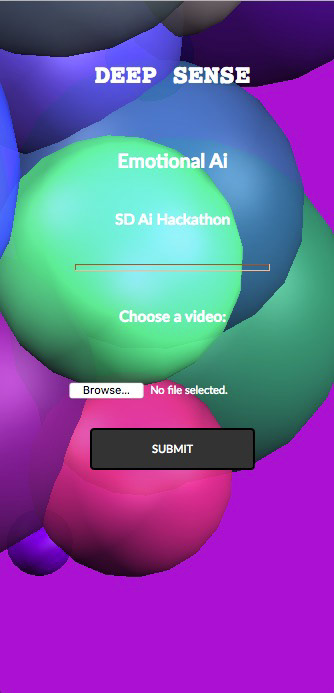
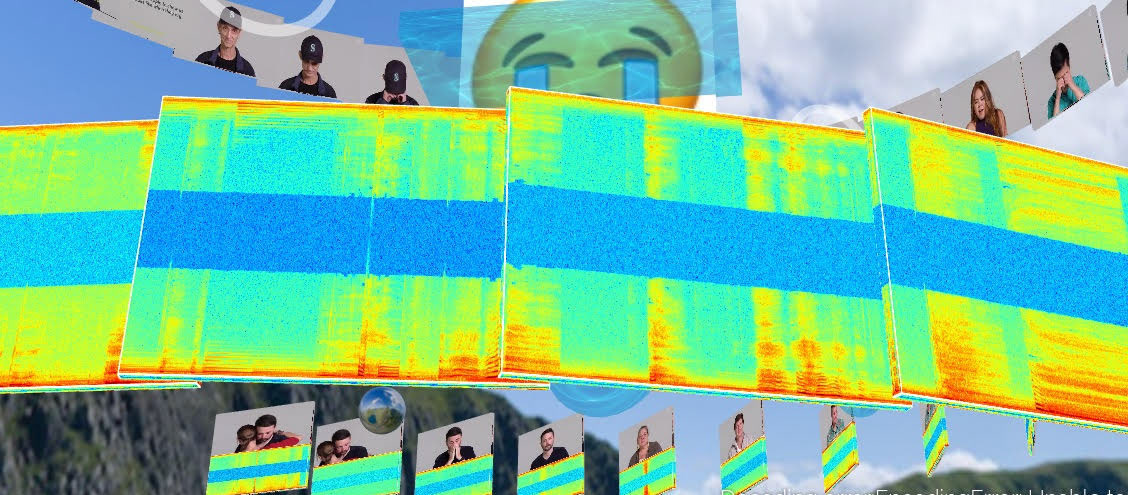
One of seven emojis is shown on the final page depending on the predicted emotion (Angry, Disgust, Fear, Happy, Sad, Surprise, Neutral). All pages are fully responsive to fit any device and are interactive to view in different perspectives by using the three mouse buttons with mouse movement. The three sets of images (video, video-audio, audio) are generated into stacked helixes to best fit varying numbers of images and to see the split frames of the video together. The background and spheres in the video input page are generated in random colors every time the page is refreshed.
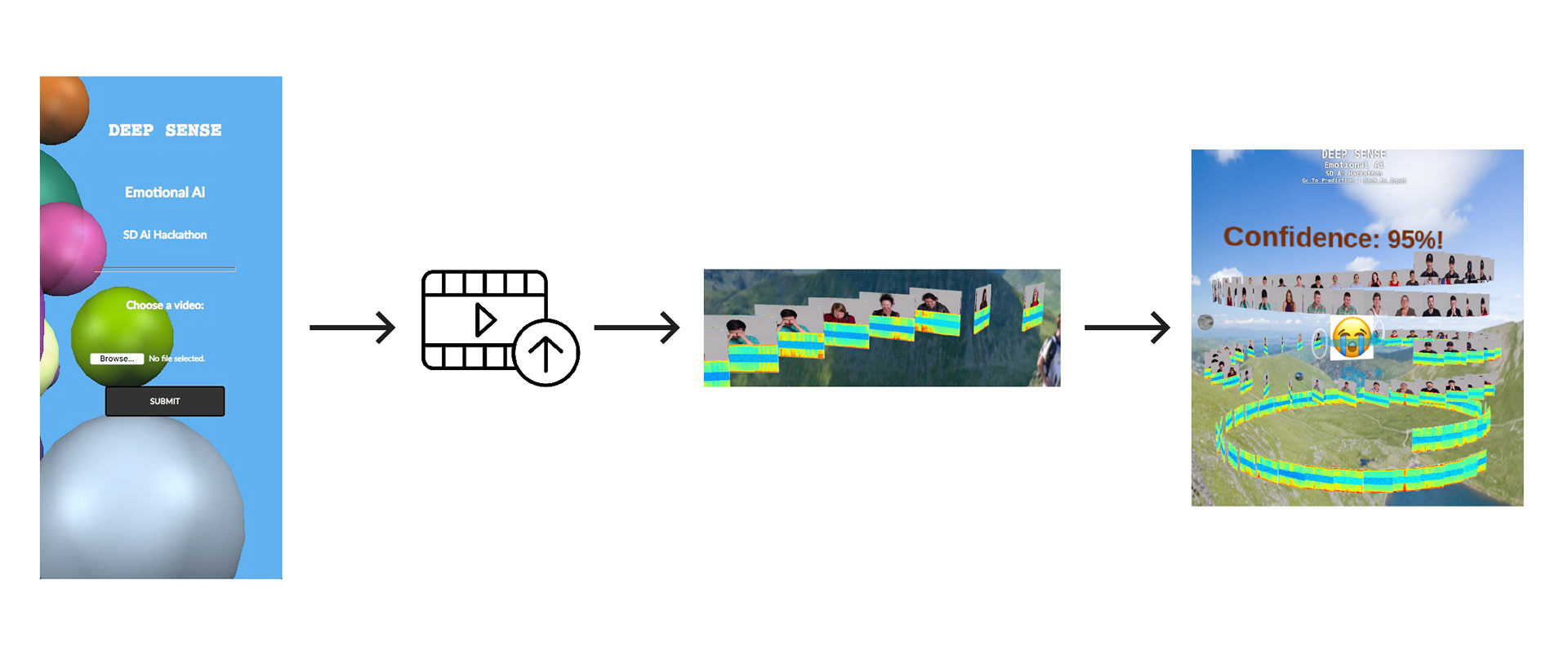
HOW IT WORKS
1. Video input preparation
The input video is split into image frames and audio frames. Depending on the considered frame rate, we split the audio into chunks corresponding to each image frame.
2. Feature preparation
After the input preparation, the audio spectrogram of the chunks are created and each video image and the corresponding audio spectrogram are stacked vertically and merged.
3. Model training
The newly created audio-video feature images are then fed into the CNN model to train the model for prediction. The training set contains 689 videos and the test set contains 335 videos.
4. Emotion prediction
The video to be predicted is prepared following Step 1 and Step 2. The trained model is applied to all of the considered frames. The rank 1 predictions lead to the final consensus-based prediction.
The input video is split into image frames and audio frames. Depending on the considered frame rate, we split the audio into chunks corresponding to each image frame.
2. Feature preparation
After the input preparation, the audio spectrogram of the chunks are created and each video image and the corresponding audio spectrogram are stacked vertically and merged.
3. Model training
The newly created audio-video feature images are then fed into the CNN model to train the model for prediction. The training set contains 689 videos and the test set contains 335 videos.
4. Emotion prediction
The video to be predicted is prepared following Step 1 and Step 2. The trained model is applied to all of the considered frames. The rank 1 predictions lead to the final consensus-based prediction.
RESPONSIVE Video Input interface
Generated video-audio frames

prediction of the emotion represented


SCREEN RECORDED DEMO
'Sadness' - Emotional A.I. Prediction
'Sadness' - Emotional A.I. Prediction
SCREEN RECORDED DEMO
'Fear' - Emotional A.I. Prediction
'Fear' - Emotional A.I. Prediction
DETAIL VIEWS


Front End Development, Design, 3D, WebGL/Three.js: Sarah Han
Data Scientists: Pradeep Anand Ravindranath, Mihir Kavatkar
Software Engineers: Russell Tan, Heriberto Prieto
Data Scientists: Pradeep Anand Ravindranath, Mihir Kavatkar
Software Engineers: Russell Tan, Heriberto Prieto